## Abstract 本文提出一个新的视觉Transformer——swin transformer一个新的cv领域的backbone。将transformer从语言应用到视觉领域的挑战来自于两个领域之间的差距,比如视觉领域的实体尺度变化大,图像的高分辨率等。为了解决这些问题,作者提出一个层次化的Transformer,它的表示是通过移位窗口来计算的。滑动窗口的方案通过将自注意计算限制在不重叠的局部窗口,同时允许跨窗口连接,从而提高了计算效率。这种层次结构具有在不同尺度上建模的灵活性,并具有相对于图像大小的线性计算复杂度。Swin Transformer的这些特性使它能够兼容广泛的视觉任务,图像分类,目标追踪,语义分割,达到了sota水平。同时分层设计和移动窗口方法也证明对所有的mlp架构是有益的。 ## 1 Introduction 长期以来CNN都是计算机视觉的主流框架,cnn模型在尺度上,连接上,卷积形式上的改进使得cnn性能不断提升。另一方面,在NLP中目前主流的结构是Transformer,它在语言领域的成功使得人们开始将其应用在视觉领域。 在这篇文章中,寻求拓展Transformer的应用,使其作为cv任务的一个通用的backbone。在nlp中的模型转化到cv中的重大挑战有两个方面。 - 尺度问题:视觉实体的拥有不同的尺度,目前transformer都是固定的。 - 高分辨率问题:目前密集型预测任务,例如图像分割,需要在像素级别做预测。自注意力计算复杂度和图像尺寸是平方关系。 **关键点1:层次化** 为了解决上述问题,提出一个Swin Transformer,构造层次化feature map,计算复杂度和图像尺寸是线性关系。 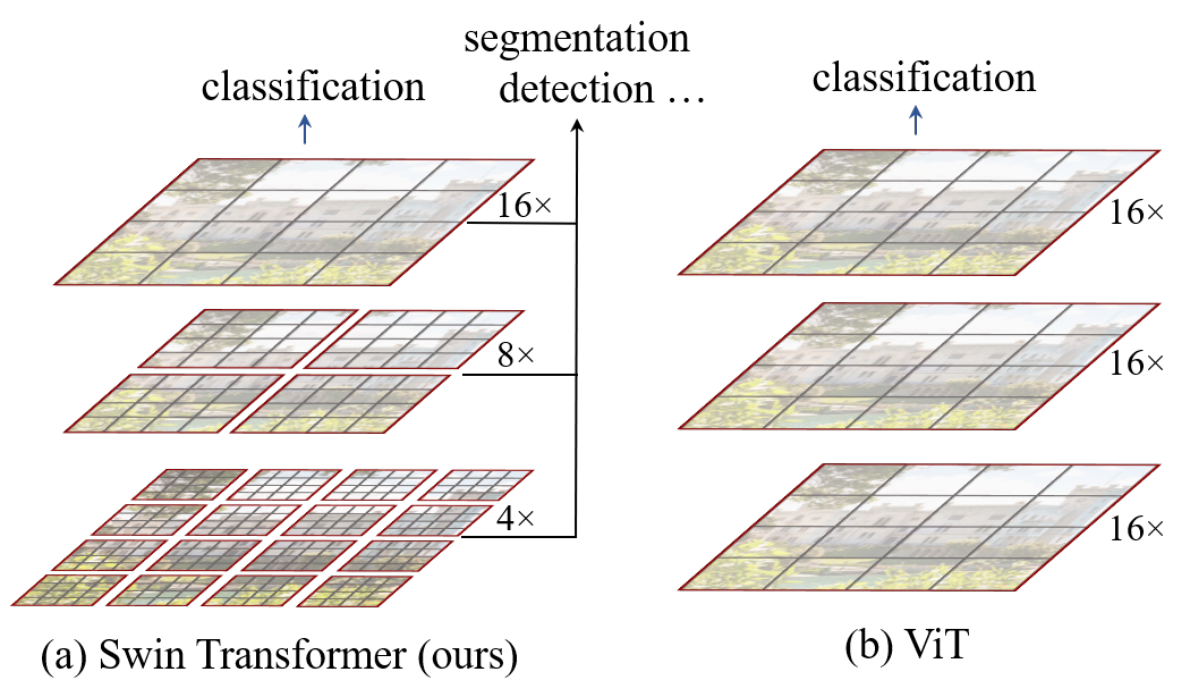 (a)Swin Transformer通过在更深的层中合并图像块(灰色部分)来构建分层feature map,并且由于只在每个local窗口中计算attention,因此对输入图像大小具有线性计算复杂度(红色部分)。因此,它可以作为图像分类和密集识别任务的通用骨干。 (b)相比之下,以往的视觉transformer产生的是单一的低分辨率特征图,由于全局自注意计算,输入图像尺寸的计算复杂度为二次。 **关键点2:平移窗口** 通过滑动窗口的方式,使得每个local窗口,可以与临近的窗口产生交互关系,扩大其关联范围。  在l层(左)中,采用规则的窗口划分方案,在每个窗口内计算自注意。在下一层l + 1(右)中,窗口分区被移位,产生了新的窗口。新窗口的自注意计算跨越了之前l层窗口的边界,提供了它们之间的连接。移位窗方法比滑动窗方法有更低的延迟,但在建模能力上是相似的。 Swin Transformer在图像分类、目标检测和语义分割等识别任务上都取得了较好的性能。 ## 2 Related Work ### 2.1 cnn及相关变体 **backbone** AlexNet [39] VGG[52]、GoogleNet[57]、ResNet[30]、DenseNet、HRNet [65], and EfficientNet [58]. **卷积核** 深度卷积[70]和变形卷积[18,84]。 ### 2.2 基于self-attention的backbone 使用self-attention来替代流行的ResNet中的部分或全部空间卷积层 ### 2.3 CNN结构引入self-attention/transformer 用self-attention或Transformer来增强标准的CNN架构。自注意层可以补充骨干网络或头网络,提供编码远距离或异构交互的能力。目前在目标检测、实例分割都有应用。 ### 2.4 基于视觉backbone的transformer ViT的开创性工作直接将Transformer架构应用于非重叠中等大小的图像块进行图像分类。 ## 3 Method ### 3.1 Overall Architecture 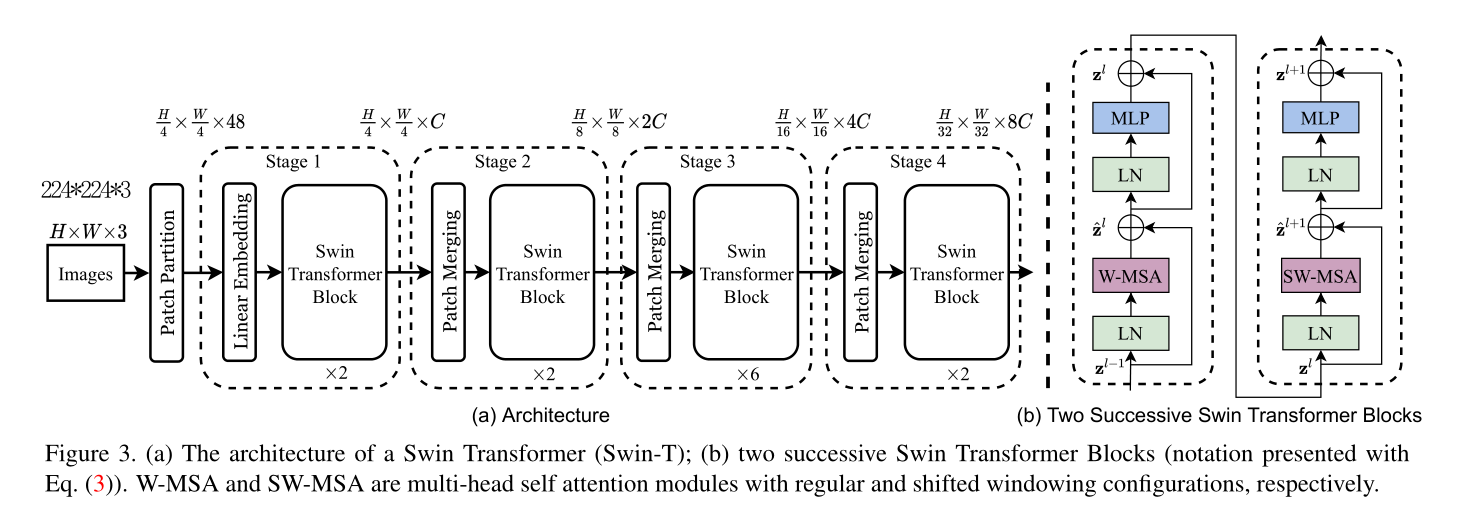 最后编辑:2024年04月23日 ©著作权归作者所有 赞 0 分享

最新回复