 [ConvNeXt论文: ](https://arxiv.org/abs/2201.03545 "convnext论文")https://arxiv.org/abs/2201.03545 ## 1 Abstract 在21世纪20年代,vision transformer,特别是像swin transformer这样的层级transformer,开始取代卷积神经网络,成为通用视觉骨干的首选。人们普遍认为,vision transformer更准确、更高效、更可伸缩。 本文提出了ConvNeXts,这是一种纯粹的卷积神经网络模型,可以在多个计算机视觉基准上与最先进的swin transformer竞争,同时保持标准ConvNet的简单性和效率。 ## 2 Introduction 回顾21世纪10年代,这十年深度学习进步飞快,主要驱动因素是神经网络的复兴,尤其是卷积神经网络(ConvNets)。在过去的十年里,视觉识别领域成功地从工程特征转向了设计(ConvNet)架构。VGG, Inception, ResNet, DenseNet, MobileNet 这些经典模型专注于准确性、效率和可扩展性的不同方面,推广了许多有用的设计原则。 卷积神经网络应用在视觉领域并不是一个巧合。卷积神经网络的几个归纳偏置,例如局部性、平移不变性非常适合计算机视觉领域。同时采用滑动卷积核的方式,权值共享也使得参数量是固定的。这些特点都使得卷积神经网络在视觉领域大放异彩。 对于2020年代兴起的vision transformer,如果没有ConvNet归纳偏差,一个普通的ViT模型在作为一个通用的视觉主干方面面临着许多挑战。最大的挑战是ViT的全局注意力设计,它相对于输入大小具有二次复杂度。这对于ImageNet分类可能是可以接受的,但对于高分辨率的输入很快变得难以处理,因此对于超分辨率,密集预测等方面存在困难。 为了解决这一问题,提出了层次化的swin transformer的结构。例如,“滑动窗口”策略(例如,本地窗口内的注意力)被重新引入到transformer中,使它们的行为更类似于convnet。Swin Transformer首次证明了Transformers可以被用作通用视觉主干,并在图像分类之外的一系列计算机视觉任务中实现最先进的性能。 在这项论文中,作者调查了ConvNet和Transformer之间的架构差异,弥合ConvNet在ViT前和ViT后的差距,并测试纯ConvNet所能达到的极限。作者从一个经过改进的程序标准ResNet(例如ResNet50)开始。逐步将架构“现代化”。 ## 3 Modernizing a ConvNet: a Roadmap 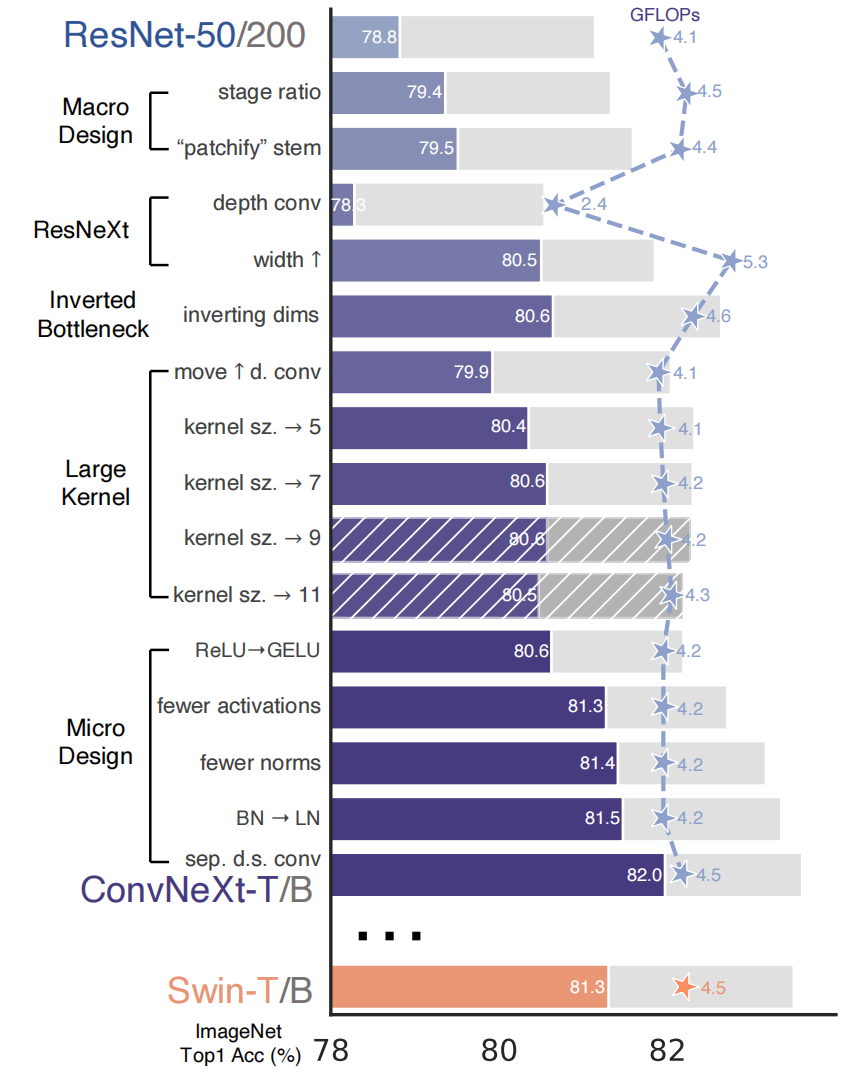 在这部分,作者采用了提供了一个从ResNet到ConvNet的轨迹,展示了在基础的ResNet上添加各种Track,提高网络的性能。作者对比ResNet-50/Swin-T,这两个模型FLOPS在4.5×10^9左右,在中间过程中可以看到模型大小尽可能保持在这个尺度,在最终的结果上,ConvNeXt-T以和Swin-T相同的参数量,在Image-1k上面达到了82%的准确率,超过Swin-T的81.3%(+0.7%) ### 3.1 Training Techniques 在Transformer中,采用了许多数据增强方式,新的优化器,大规模数据集上的预训练,warm-up等一些方式,因此为了保持与transformer进行性能对比,因此我们在resnet-50的baseline上面也采用这些优化的训练方式。 - AdamW优化器 - 数据增强:Mixup [85], Cutmix [84], RandAugment [12], Random Erasing - 正则化方法: Stochastic Depth, Label Smoothing 通过以上方式,得到ResNet50的Baseline,可以明显看到该模型比原有模型有着明显提升。 **ResNet-50 model from 76.1% [1] to 78.8% (+2.7%)** ### 3.2 Macro Design 模型的宏观结构设计 #### 3.2.1 采用Swin-T每个Stage的Block比例 原始的ResNet模型每个Stage的比例是**(3 4 6 3)**,而Swin Transformer-Large每个Stage的比例是**(1 1 3 1)**,因此作者根据swin-T将ResNet50每个stage的block比例调整为**(3 3 9 3)**. **通过改变比例,准确率从78.8%提升到79.4%.** #### 3.2.2 采用Swin-T的patch输入 - 在标准的resnet中,首先采用conv2d 7*7 stride2对图片进行采样,后面添加一个max polling kernel=2.这种方式相当于在一开始进行4倍的降采样。 - 在VIT中,不采用卷积池化操作,直接采用conv2d 16*16 stride16将图片分割成许多16*16大小的patch。 - 在Swin-T中,采用了更小Conv2d 4*4 stride=4, 将图片分割成更小更多的patch。 作者参考transformer中的patch思想, 直接利用con2d 4*4 stride=4进行处理,达到降采样4倍的相同效果。 **通过改变输入,准确率从79.4%提升到79.5%** ### 3.3 采用ResNeXt中的分组卷积 ResNext在经典Resnet的基础上采用了**分组卷积(group convulation)**,从而提升resnet的性能。那么显然我们提升resnet50的性能也要加上这个。 在本文中,作者采用了mobilenet中使用的DW卷积。DW卷积也就是分组卷积的特殊情况,分组的数量==通道的数量。也就是每个通道分别采用一个深度为1的卷积核进行卷积操作,DW卷积大大的降低了参数数量,其中假设将通道分成n组,那么计算量将减少到$$\frac{1}{n}$$。显而易见,参数数量减少会导致模型准确率降低,此时以2.4GFLOPs的参数量,准确率降低到78.3%。为了弥补损失,作者将通道数从原来的64增加至96(和Swin-T一致,这里的base width是指stem后的特征大小)。 **此时模型的FLOPs有所增加(5.3G),模型性能提升至80.5%。** ### 3.4 改用EfficientNet中的Inverted bottleneck 如果把self-attention看成一个dw conv的话(这里忽略self-attention的linear projection操作),那么一个transformer block可以近似看成一个inverted bottleneck,因为MLP等效于两个1x1 conv,并且MLP中间隐含层特征是输入特征大小的4倍(expansion ratio=4)。inverted bottleneck最早在MobileNetV2中提出,随后的EfficientNet也采用了这样的结构。ResNet50采用的是正常的residual bottleneck,这里将其改成inverted bottleneck 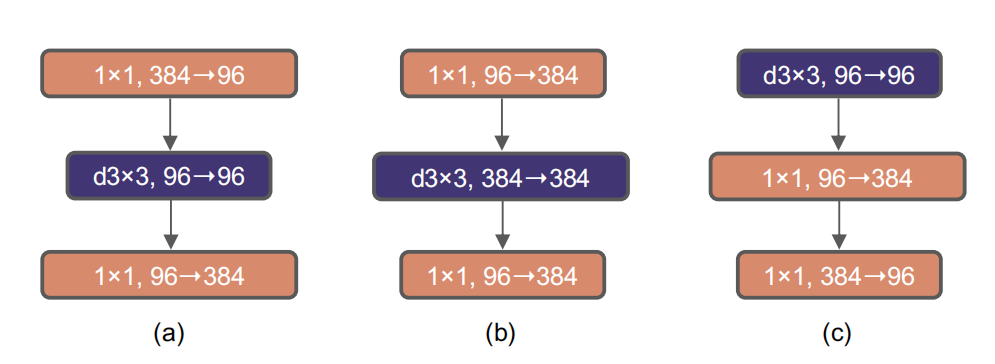 图(a)变成图(b),虽然dw conv的计算量增加了,但是对于包含下采样的residual block中,用于shortcut的1x1 conv计算量却大大降低,最终模型的FLOPs减少为4.6G。 **这个变动对ResNet50的影响较小(80.5%->80.6%)。** ### 3.5 采用large kernel size 自从VGG之后,主流的CNN往往采用较小的kernel size,如3x3和5x5, VGG提出感受野的概念,通过两个3*3的卷积代替5*5的卷积,在感受野不变的情况下,减少计算量。因此后来的网络通常也不采用较大的卷积核。 #### 3.5.1 Moving up depthwise conv layer 如果想使用更大的卷积核,那么需要上移dw卷积。否则这个inverted结构中,如果先用1*1升维,再用大卷积核,那么计算量就得炸了,因此考虑将dw卷积上移动,如上图(b) -> (c)所示。复杂/低效的模块(MSA、大型内核conv)将拥有较少的通道,而高效、密集的1×1层将完成繁重的工作。 **单纯移动定dw卷积导致FLOPs下降到4.1G,性能暂时降低到80.6%->79.9%(-0.7%)** #### 3.5.2 Increasing the kernel size. Swin-T采用的window size为7x7,这比3x3 conv对应的windwo size要大得多,所以这里考虑采用更大的kernel size。这里共实验了5种kernel size:3x3,5x5,7x7,9x9和11x11。实验发现kernel size增加,模型性能有提升,但是在7x7之后采用更大的kernel size性能达到饱和。所以最终选择7x7,这样也和Swin-T的window size一致。 **通过更大的卷积核,此时性能回到80.6%与之前一致** 到此位置,模型的大体结构基本确定,从上面几个改进中也可以看出,swin-t模型的设计思想都可以映射到conNet,而且也可以取得更好的效果。 ### 3.6 Micro Design 模型的微观结构设计 在micro design的设计中,作者主要探索了激活函数和标准化层的设计。 #### 3.6.1 使用GELU替代RELU NLP和vision体系结构之间的一个差异是要使用哪些激活函数的细节。随着时间的推移,已经开发出了许多激活函数,但校正线性单元(ReLU)[46]由于其简单高效,仍然广泛用于convnet。高斯误差线性GELU,可以被认为是ReLU的一个更平滑的变体,在BERT[16]和OpenAI的GPT-2[49],以及最近的ViT都有使用。在作者提出的ConvNext中,ReLU也可以用GELU替代。 **尽管准确率保持不变(80.6%)。** #### 3.6.2 使用更少的激活函数 Transformer和convnet的主要区别作者认为还体现在激活函数的使用。在transformer中,我们回顾一下,在其中的MLP模块,仅有2层Linear之间添加了一层GELU的激活函数;但是在卷积神经网络中,每层卷积层后面都接激活函数。作者对于基础的ConvNeXt模块的设计上,仅仅在2个1*1的卷积之间采用了GELU激活函数。 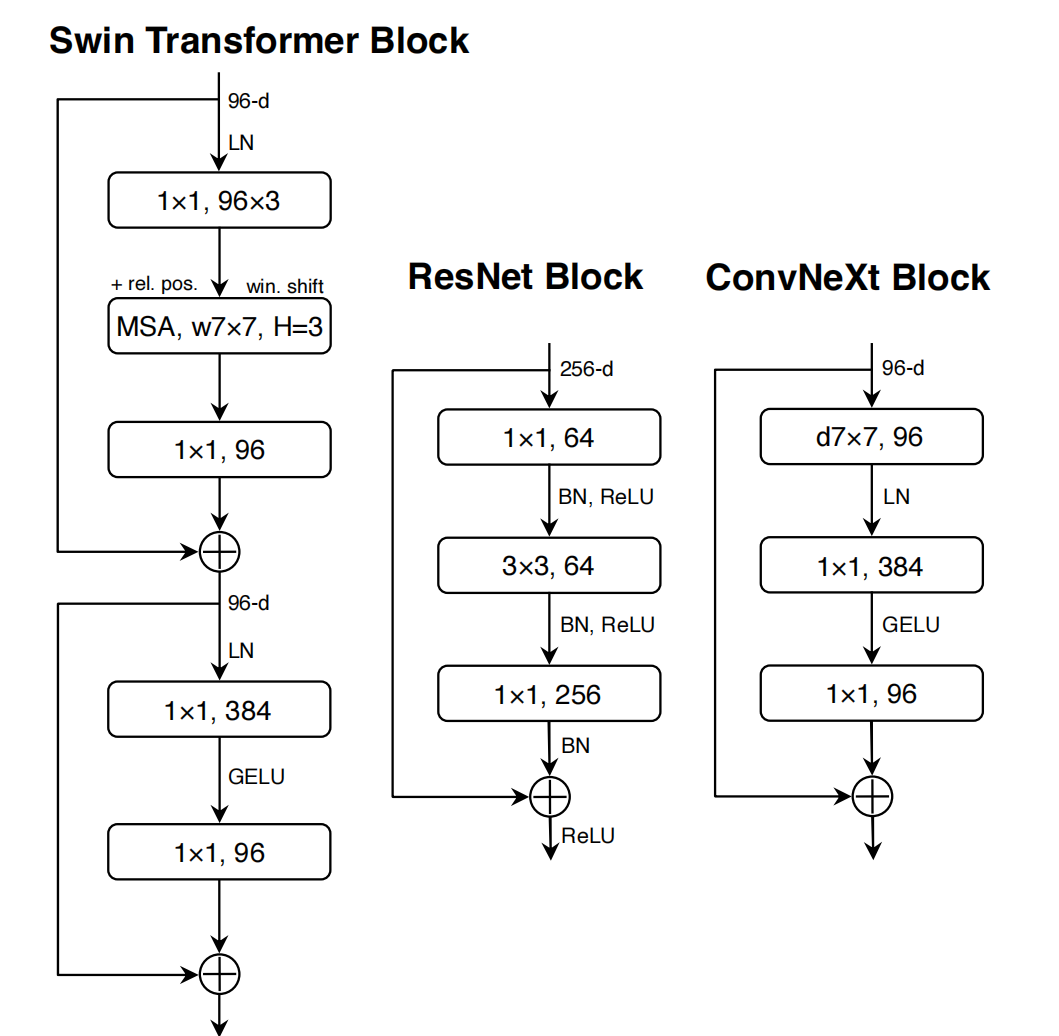 **通过这个设计,将结果提高了0.7%至81.3%,实际上与Swin-T的性能相当** ### 3.6.3 使用更少的标准化层 在这里,移除了两个BatchNorm(BN)层,在conv 1×1层之前只留下一个BN层。通过这个设计,每个ConvNext块只有一个LN层,而Swin-T有2个LN层。而作者也发现在swin-T开头加入LN并不能提升性能。 **通过这个设计,将结果提高了81.3%至81.4%,实际上超过了Swin-T的性能** #### 3.6.4 使用Layer Norm替代Batch Norm BatchNorm[35]是ConvNets中的一个重要组成部分,因为它提高了收敛性,减少了过度拟合。然而,BN还有许多复杂之处,可能会对模型的性能产生不利影响[79]。在研究标准化层[57,70,78]方面已经有过无数次尝试,但BN仍然是大多数视觉任务的首选选项。 在原始ResNet中直接用LN代替BN将导致性能下降。在对网络架构和培训技术进行了所有修改后,重新使用LN代替BN,ConvNet模型在LN训练方面没有任何困难; **事实上,代替之后性能稍好一些,准确率为81.5%** #### 3.6.5 分离下采样层 在resnet中,每个stage的第一个block承担了下采样的任务。其中3*3的卷积核使用stride=2,shortcut也进行下采样。在swin-t中,在2个stage之间,采用一个单独的patch mergeing进行下采样操作。作者在每个stage之间采用了conv2d 2*2 stride=2进行下采样。 作者进一步探索,在空间尺度变化的时候,加入LN层有助于训练的稳定性。比如在Swin-T中,在每个stage之间,在stem之后,在最后的avgpool之后,都加入了LN层。 **准确度提高到82.0%,大大超过Swin-T的81.3%。** ### 3.7 总结模型修改 作者发现了纯ConvNet,它可以在这种计算模式下优于用于ImageNet-1K分类的Swin Transformer。迄今为止讨论的设计方案都不是新颖的——在过去十年中,它们都是单独研究的,但不是集体研究的。ConvNeXt模型和Swin Transformer具有大致相同的参数,吞吐量和内存,而且不需要特殊模块,如移动窗口注意或相对位置偏差。 之后,将在模型的适应下游任务上,以及模型适应尺度上进行实验测试,看看这些是否依然能超过Swin模型。 ## 4 ImageNet实验验证 ### 4.1 网络整体结构 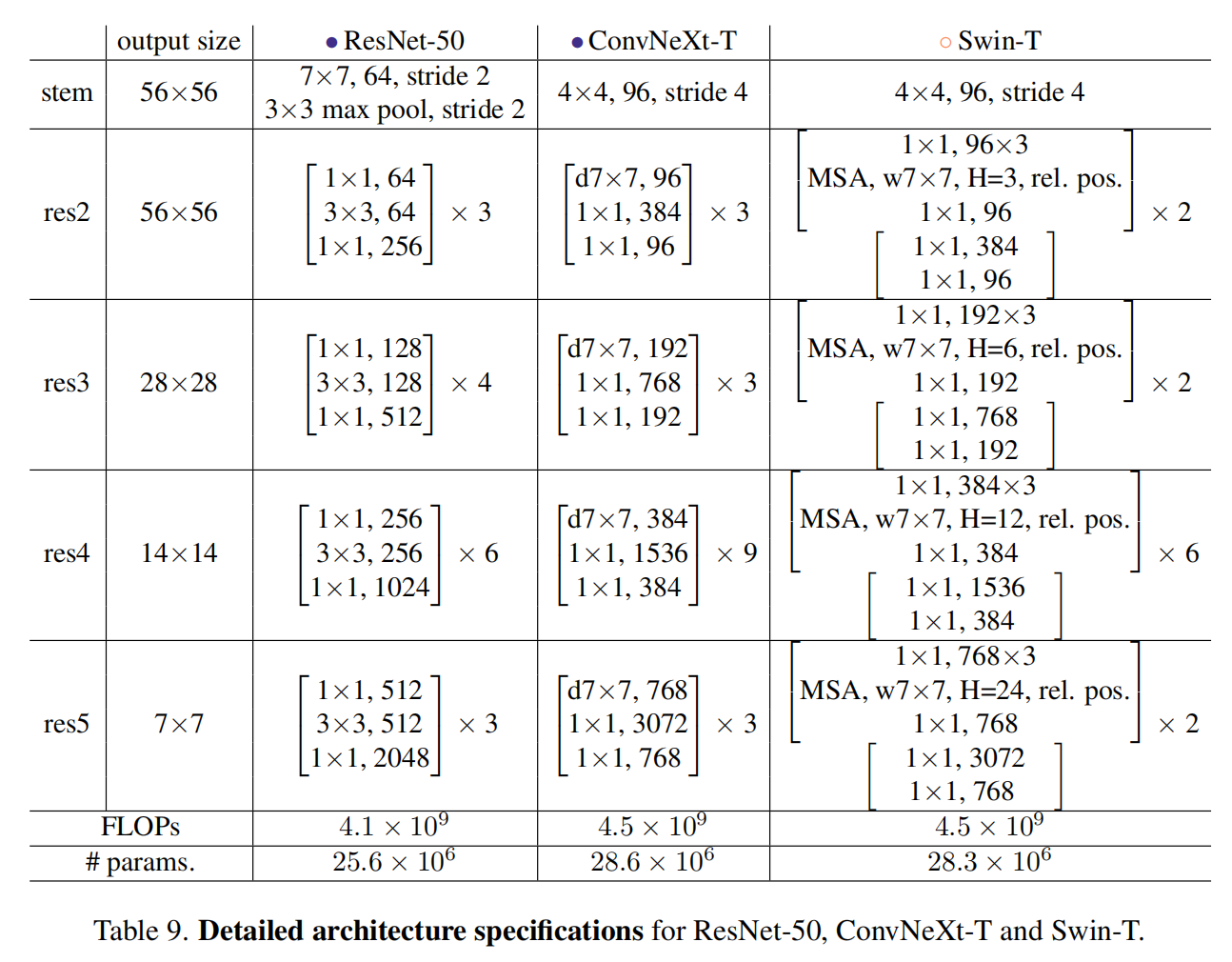 • ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3) • ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3) • ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3) • ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3) • ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3) ### 4.2 训练方式 ### 4.2.1 在ImageNet-1K上进行训练。 我们使用AdamW[43]以4e-3的学习率为300轮训练Convenxts。接下来是20轮的linear warm up和余弦衰减时间表。我们使用的批量为4096,重量衰减为0.05。对于数据增强,我们采用了常见的方案,包括Mixup[85]、Cutmix[84]、RandAugment[12]和随机擦除[86]。我们用随机深度[34]和标签平滑[65]对网络进行正则化。应用初始值1e-6的层比例[69]。我们使用指数移动平均(EMA)[48],因为我们发现它可以缓解较大模型的过度拟合。 ### 4.2.2 ImageNet-22K的预训练ImageNet-1K上进行微调 在ImageNet-22K上对Convenxts进行了90个阶段的预训练,并进行了5个阶段的warm up。 在ImageNet-1K上对ImageNet-22K预训练模型进行了30轮的fintune。我们使用AdamW,学习率为5e-5,余弦学习率计划,分层学习率衰减[6,10],无预热,批量大小为512,重量衰减为1e-8。默认的预训练、微调和测试分辨率为2242。此外,对于ImageNet-22K和ImageNet-1K预训练模型,我们以3842的更高分辨率进行微调。 与ViTs/Swin-T相比,ConvNeXts在不同分辨率下更易于微调,因为网络是完全卷积的,无需调整输入大小或插值绝对/相对位置偏差。 ### 4.3 结果对比 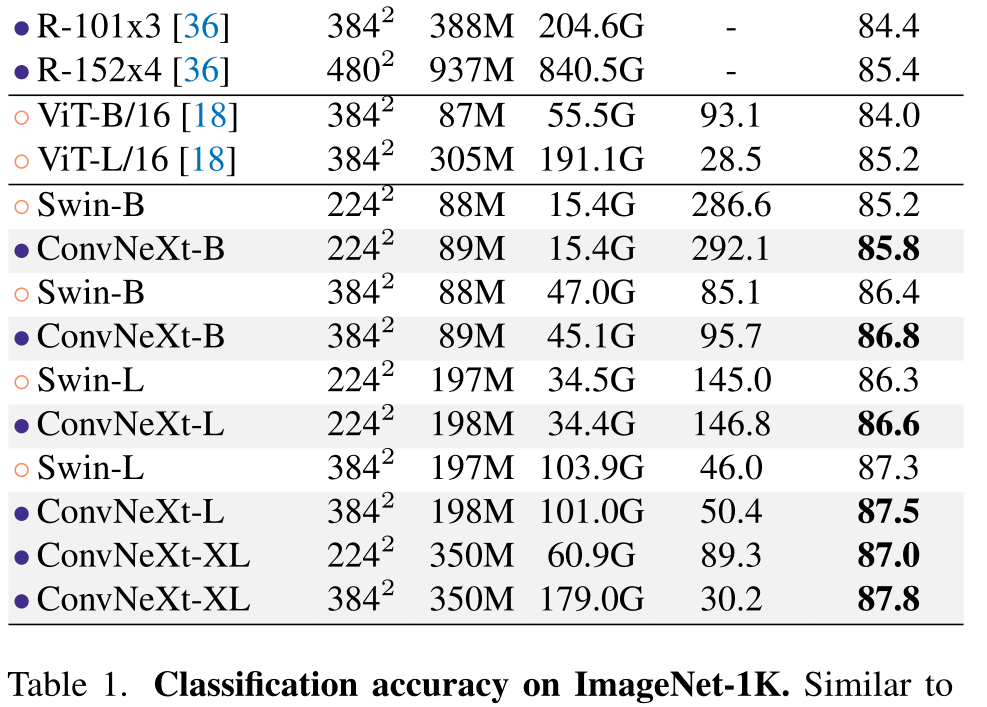 从Image-1k的分类结果可以看到,在模型参数大小相似的不同尺度模型中,ConvNext的效果均要由于swin transformer 之后的检测分割下游任务中,也可以看到类似的效果。 ## 5 总结 在2020年代,vision transformer,尤其是像Swin Transformers这样的层次化transformer,开始取代ConvNet成为通用backbone的首选。人们普遍认为,视觉转换器比ConvNet更准确、更高效、更可扩展。作者提出了ConvNeXts,这是一个纯ConvNet模型,可以在多个计算机视觉基准上与最先进的Swin Transformers竞争,同时保持ConvNet的简单性和效率。ConvNeXt模型本身并不是全新的——在过去十年中,许多设计选择都是单独进行,但不是整体考虑的。这篇论文促使人们重新思考卷积在计算机视觉中的重要性。 最后编辑:2024年04月23日 ©著作权归作者所有 赞 0 分享

最新回复