## Abstract 近年来在图像恢复领域取得了重大进展,但最先进的(SOTA)方法的复杂性也在增加。在本文中,作者提出了一个简单的baseline,它超过了SOTA方法,并且计算效率很高。为了进一步简化baseline,我们揭示了非线性激活函数,如sigmoid、ReLU、GELU、Softmax等。都是不必要的:它们可以被乘法代替或移除。因此,作者从baseline推导出一个非线性激活自由网络,即NAFNet。实验表明在GoPro数据集上的33.69dBPSNR(用于图像去模糊),超过了之前的SOTA +0.38dB,仅为其计算成本的8.4%;SIDD上的40.30dB PSNR(用于图像去噪),超过了之前的SOTA +0.28dB,而其计算成本不到SIDD的一半。 ## 1 Introduction 作者提出,尽管新的降噪方法层出不穷,但是系统复杂度不断提升。作者将系统复杂度分成**block内部**的复杂度和**block间**的复杂度两部分组成。 block之间的构型主要有以下3种: 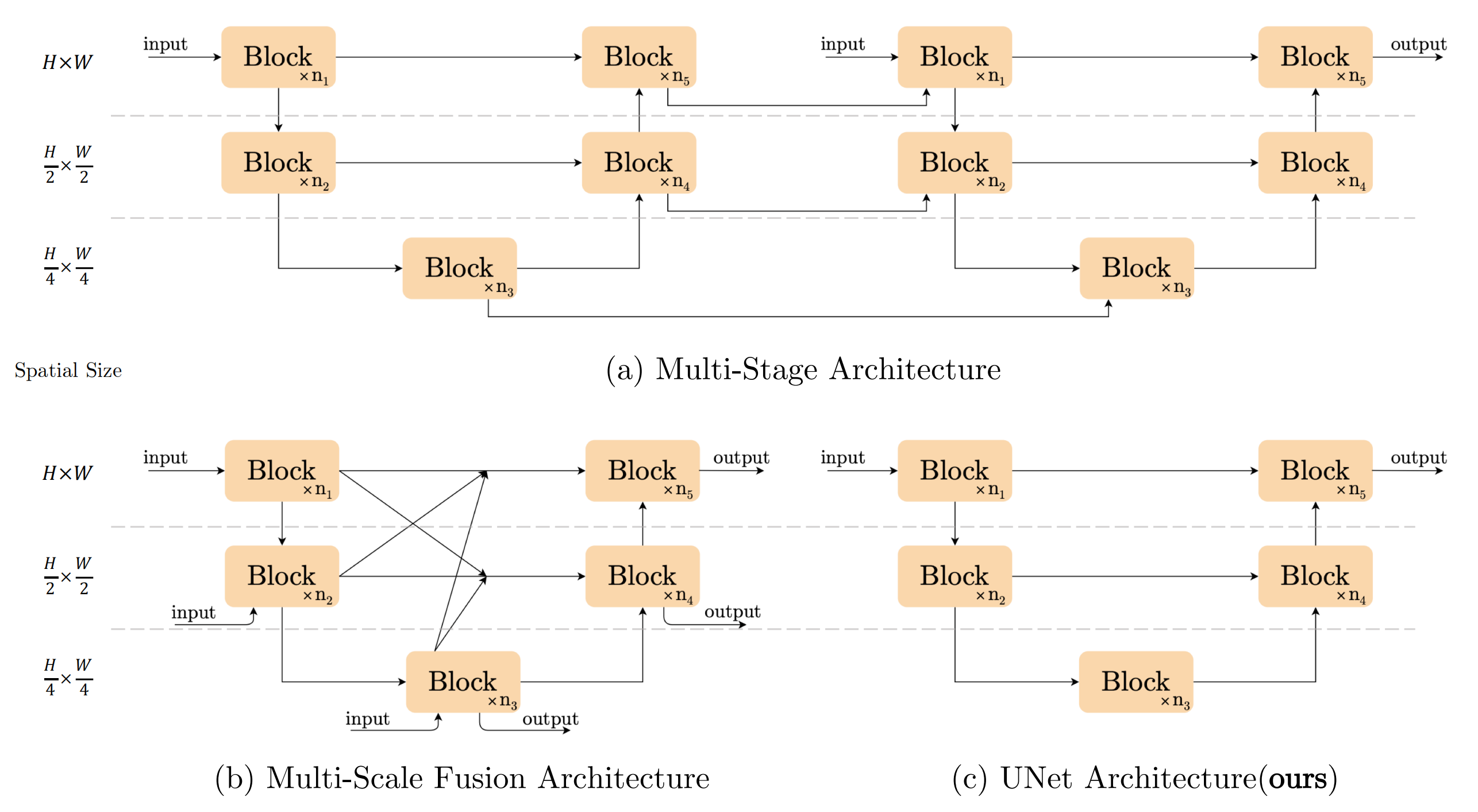 - 第一种为多阶段结构,采用序列化的方式去堆叠UNet网络结构 - 第二种是多尺度融合结构,融合了摆脱那个尺度的特征细腻些。 - 第三种是传统UNet结构,作者在本文中采用的方式, 作者在本文中意在降低块内和块间的复杂度,从普通块中,作者添加/替换了SOTA方法的组件,并验证了这些组件带来了多少性能增益。通过广泛的消融研究,我们提出了一个简单的基线,如图所示。 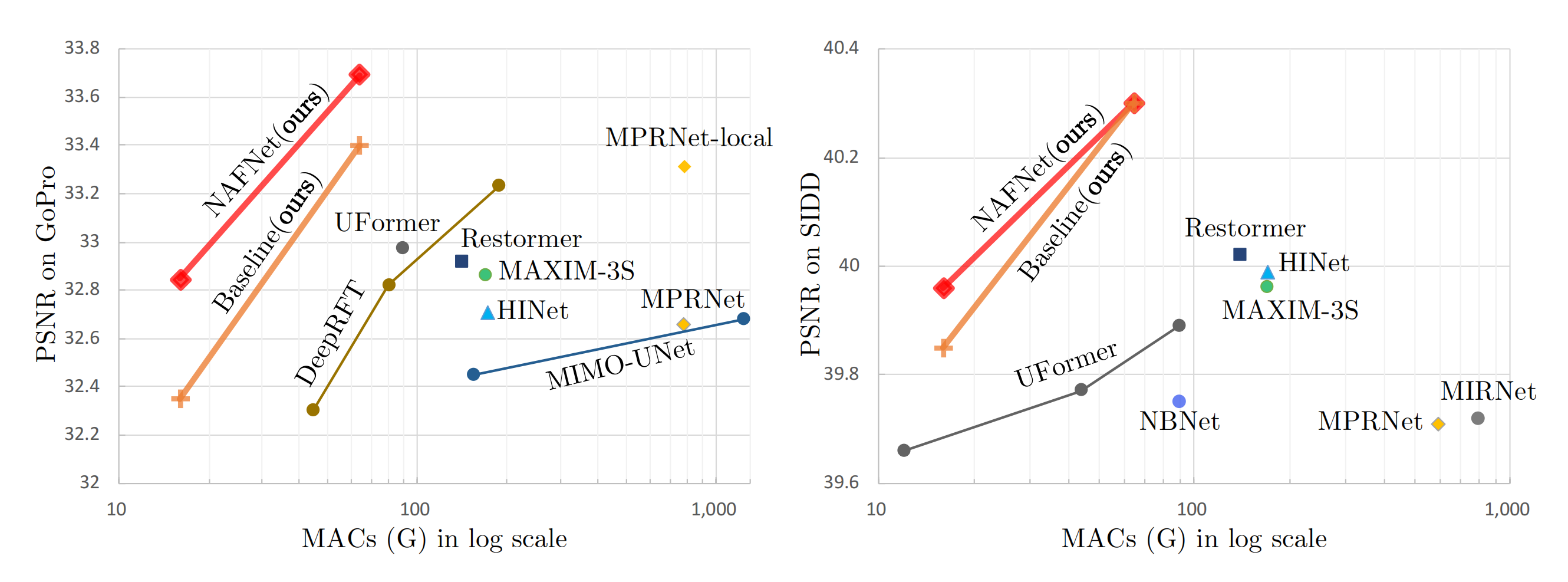 可以看到,作者提出的方法相较于之前的SOTA方法,有着更好的效果和更少的计算复杂度。本文的主要贡献主要有以下两点: 1. 通过分解SOTA方法和提取基本的比较,我们形成一个基线降低系统复杂性,可以超过以前的SOTA方法和较低的计算成本。 2. 通过揭示GELU、通道注意力到门控线性单元之间的联系,我们通过去除或替换非线性激活函数(如sigmoid、ReLU和GELU)进一步简化了基线,并提出了一个非线性无激活的网络,即NAFNet。虽然它被简化了,但它可以匹配或超过基线。据我们所知,这是第一个工作证明,非线性激活函数可能不是必要的SOTA计算机视觉方法。这项工作可能有可能扩展SOTA计算机视觉方法的设计方式。 ## 2 Build A Simple Baseline 为了降低块间的复杂性,作者采用了经典的具有跳过连接的单个UNet结构,如上图(c)的结构所示。作者认为模型的整体结构不会成为限制模型性能的瓶颈,后续的实验也证明了这个想法。作者构建这个模型的原则是的原则是——**“Not to add entities if they are not necessary.”** ### 2.1 A Plain Block 作者从一个具有最常见组件的Block开始构建,包含卷积、ReLU和shortcut,如下图的(b)所示。 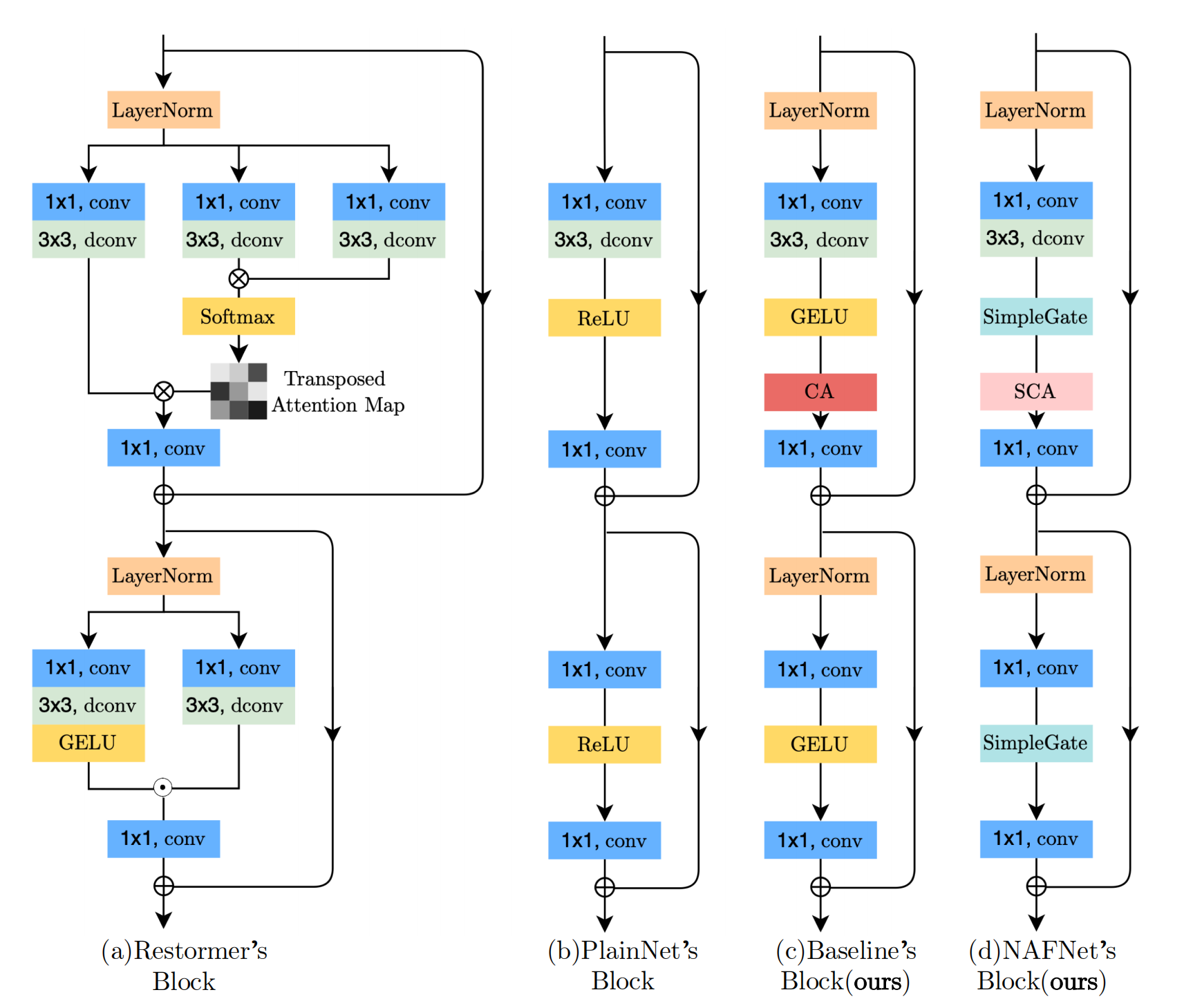 为了简单起见,作者将其命名为Plain Block。作者使用卷积网络而不是transformer是基于以下考虑因素。首先,尽管transformer在计算机视觉中表现出良好的性能,但一些论文(例如ConvNext)声称它们可能不是实现SOTA结果所必需的。其次,深度卷积比self-attention机制更简单。第三,本文并不是为了讨论transformer和卷积神经网络的优缺点,而只是为了提供一个简单的基线。关于注意力机制的讨论将在后面的小节中提出。 ### 2.2 Normalization Normalization在high level计算机视觉任务中被广泛采用,在low level视觉中也有一种流行趋势。虽然降噪之类任务普遍放弃了batch norm,因为小批量大小可能会带来不稳定的统计,但一些方式(half instance)重新引入了instance norm,避免了小批量的问题。然而添加instance norm并不总是会带来性能的提高,并且需要手动调优。不同的是,在transformer的广泛应用下,Layer norm被越来越多的方法使用。基于这些事实,我们推测Layer Norm可能对降噪方法至关重要,因此我们在上述的plain block中添加了Layer Norm。即使是在学习率上增加了10×,但由于添加了Layer Norm训练仍然可以顺利进行,同时更大的学习速率带来显著的性能增益:在SIDD数据集上提升了+0.44dB(39.29dB~39.73dB) ### 2.3 Activation Plain block中的激活函数Relu广泛应用于计算机视觉。然而,在SOTA方法中,存在着用GELU取代ReLU的趋势。这个替换也在我们的模型中实现了。在SIDD上的性能稍有下降-0.02dB(从39.73dB到39.71dB),但是它在GoPro上带来了0.21dB的性能提高(31.90dB至32.11dB)。作者保留了采用GELU替代RELU的方式,因为因为它保持了图像去噪的性能,同时给图像去模糊带来了显著的增益。 ### 2.4 Attention 考虑到近年来transformer在计算机视觉中的普及,注意力机制是transformer在block内部结构设计中不可避免的一个问题。注意力机制有许多变体,作者在这里只列出其中的少数几种。例如ViT采用的普通自注意机制,通过所有特征的线性组合生成目标特征,这些特征之间的相似性加权。因此,每个特征都包含全局信息,而随着特征图的大小,它存在二次计算复杂度。一些图像恢复任务以高分辨率处理数据,这使得普通的self-attention不实用。另外,swin-T只在一个固定大小的局部窗口中应用self-attention,以减轻计算量增加的问题,虽然它缺乏global信息。作者不采取基于窗口的attention机制,因为局部信息可以被Plain block中的深度卷积(ConvNext)很好地捕获。 不同的是,Restormer将空间注意修改为通道注意,避免了二次方的计算量问题,同时保持每个特征中的全局信息。它可以看作是通道注意力的一种特殊变体。受Restromer的启发,作者实现了一个普通的通道注意力满足计算效率的要求。并将全局信息带到特征图中。此外,在图像恢复网络(MPRNet)中验证了通道注意的有效性,因此作者将channel attention添加到普通块中。它在SIDD[1]上带来+0.14dB(39.71dB到39.85dB),在GoPro[25]数据集上提供+0.24dB(32.11dB到32.35dB)的增益。 ### 2.5 Summary 到目前为止,作者从头开始构建了一个简单的baseline,该结构的block分别如图2c和图3c所示。基线中的每个组件都是微不足道的,例如,层归一化、卷积、GELU和通道注意。但是这些琐碎组件的组合导致了一个强大的baseline:它可以超过之前在SIDD和GoPro数据集上的SOTA结果。 ## 3 Nonlinear Activation Free Network 上面描述的baseline简单且有竞争力,但是否有可能在进一步简化的同时进一步提高性能?它能在不造成性能损失的情况下更简单吗?我们试图通过寻找一些SOTA方法的共性来回答这些问题。作者发现,在许多SOTA的论文中,广泛使用了Gated Linear Units(GLU)门控线性单元,因此可能这对于提升是有帮助的。 ### 3.1 Gated Linear Units 门控线性单元可以表示为如下式子: $$Gate(X, f, g, \sigma) = f(X) \cdot \sigma(g(X))$$ 其中X代表了输入的feature map,f和g是两个线性变换,$$\sigma$$代表了非线性激活函数。增加GLU会提升性能,但是会进一步增加块内计算复杂度,这与作者的期待不符合,因此作者又回顾了GELU激活函数的设计。 $$GELU(x)=x\Phi(x)$$ 其中$$\Phi$$表示了标准正态分布函数的累计函数,因此GELU激活函数可以近似成以下式自: $$0.5x(1+tanh[\sqrt{\frac{2}{\pi}}(x+0.044715x^3)])$$ 作者认为,GELU激活函数可以看作是GLU单元的一种特殊情况,f和g是2个恒等变换,$$\sigma$$作为非线性的激活函数,通过这种相似性,作者从另一个角度推测GLU可以看作是激活函数的泛化,它可能能够取代非线性激活函数。 进一步,作者认为GLU本身包含了非线性,并不是依赖于$$\sigma$$这个非线性激活函数, 即是说给它移除, $$Gate(X) = f(X) \cdot g(X)$$也包含了非线性。 基于以上说的这两点,作者提出一个简单的GLU的变体,直接在channels维度将feature map分成两部分,然后进行一个element-wise的乘法即可,可以如下表示。 $$SimpleGate(X,Y)=X \cdot Y$$ 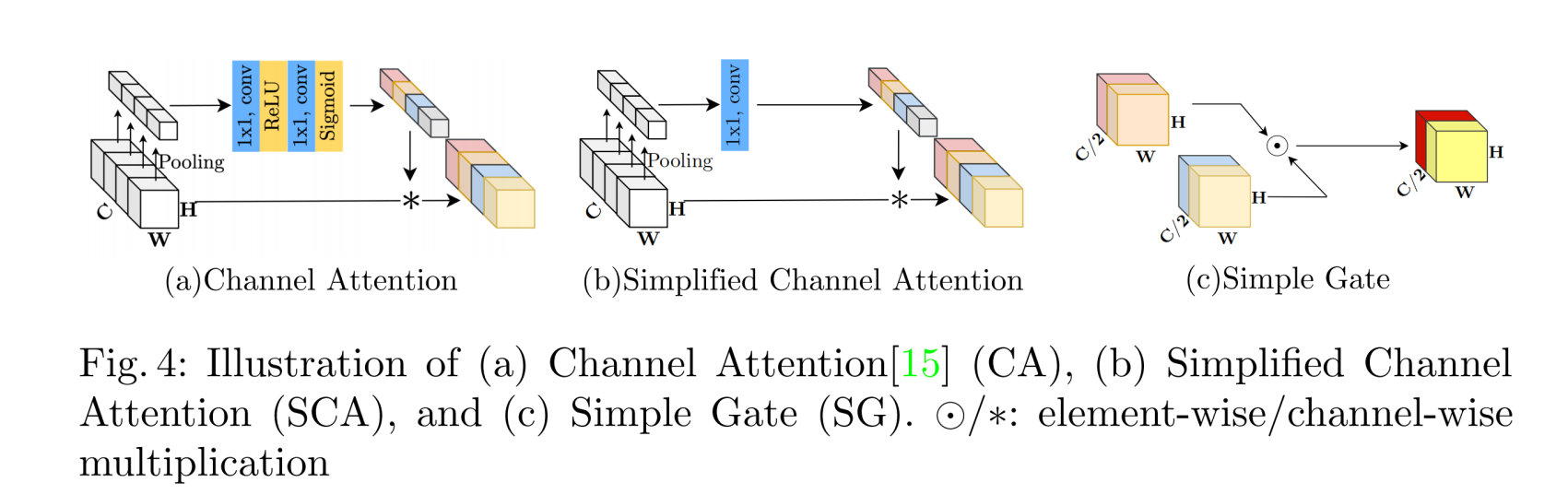 作者将baseline中的GELU替换为提出的SimpleGate,图像去噪(在SIDD上)和图像去模糊(在GoPro数据集上)的性能分别提高了0.08dB(39.85dB至39.93dB)和0.41dB(32.35dB至32.76dB)。结果表明,GELU可以被SimpleGate所取代。 ### 3.2 Simplified Channel Attention 在上一章节作者提出的Baseline中采用channel-attention机制,这个机制可以详细看上图(a)的表示结果。首先对每个channels进行AvgPooling,得到每个channels的权重,然后经过2个卷积和激活函数,得到每个channels分配的注意,将数值点乘原来的feature map上去,该方法可以用以下式子表示: $$CA(X)=X \cdot \sigma(W_2max(0, W_1pool(X)))$$ 如果将后面这部分统一看成一个非线性的激活函数,那么上面式子可以简化成 $$CA(X)=X\Phi(X)$$ 注意到上面CA的式自和GELU非常类似,这使得作者将CA作为GLU的一种特殊情况,它可以像上一小节中的GLU一样进行简化。通过保留通道注意的两个最重要的作用,即聚合全局信息和通道信息交互,作者提出了简化的通道注意。 $$SCA(X)=X*Wpool(X)$$ 显然,简化的通道注意比原来的更简单。作者为了进行公平的比较,我们调整了CA的中间特征维数,使计算成本与SCA保持一致。虽然它更简单,但没有性能损失:SIDD上的+0.03dB(39.93dB到39.96dB),GoPro上的+0.09dB(32.76dB到32.85dB)。 ### 3.3 Summary 从上一节中提出的baseline开始,作者进一步简化了GLU,用SimpleGate和SCA代替了GELU和CA,而不损失性能。作者强调,在简化后,就没有非线性激活函数(如ReLU、GELU、Sigmoid等)。在网络中。所以我们称这个基线**无非线性激活网络——即NAFNet**。虽然没有非线性激活函数,但它可以匹配或超过baseline。 ## 4 Conclusions 通过分解SOTA方法,提取基本组件并将其应用于plain block上。所得到的baseline在图像去噪和图像去模糊任务上达到了SOTA的性能。通过对baseline的分析,作者发现它可以进一步简化:其中的非线性激活函数可以被完全替换或去除。由此,我们提出了一个无非线性激活网络,NAFNet。虽然简化了设计,但其性能等于或优于baseline。我们提出的baseline可能有助于研究人员评估他们的想法。此外,这项工作有可能影响未来的计算机视觉模型设计,因为我们证明了非线性激活函数并不是实现SOTA性能所必需的。 最后编辑:2024年04月23日 ©著作权归作者所有 赞 0 分享

最新回复