## 基于Transformer的多阶段融合盲降噪网络 ### 0 背景 图像降噪是一个计算机视觉的基础研究领域,图像在通过传感器获取的过程中,不可避免的引入各种类型的噪声信号,因此如何去除这些噪声获得更加真实的图像至关重要。近些年来,基于深度学习的图像降噪方法已经在图像降噪领域打败传统的降噪方法。但随着这些深度学习方法效果的不断提升,模型的参数量也随之明显增长。Megvii这次提出的推出图片降噪方向的相关赛题——小模型盲降噪主题,通过实现一个100KB以下参数量的网络,达到更好的降噪效果。 ### 1 介绍 本文提出的方法采用了传统的UNet网络架构,在网络block的设计上采用了目前热门的transformer,通过基于channel维度的self-attention机制,避免计算复杂度与图像尺寸的平方增长,实现transformer在小参数模型的应用。为了实现不同level信息更好的特征融合,在UNet架构上面,通过左侧添加辅助的下采样分支,利用pixel和双线性差值的方式融合下采样信息,实现浅层信息更好的向深层流动。在UNet架构右侧上采样部分,通过添加注意力机制,对个阶段不同尺寸的feature map计算注意力,最终实现多个阶段的图像特征融合。为了实现UNet左侧下采样的表层信息,和经过多层网络右侧的上采样分支实现更好的信息融合,在UNet中间shortcut连接上面添加了Megvii提出的SSA结构,通过将左侧下采样分支的特征投影到右侧上采样分支的特征空间中,达到低维特征融合高维特征的目的。最终为了保持参数量不变,提升模型效果,对每个block采用了权重共享的方式,进一步提升了网络的降噪效果。 ### 2 Block的构建 通过前期对图像降噪模型的调研,目前最广泛应用的降噪网络设计上,均采用了UNet的设计思路(如NAFNet, Restormer, NBNet, MIRNet)。因此,我们在构建网络的时候,考虑采用最基础的UNet整体架构在此基础上进行进一步的优化。  #### 2.1 基于CNN的Block构建 对于模型中的block设计上,我们考虑block内部的复杂度将是影响整个网络参数量的决定性因素,因此期望通过采用轻量化的网络设计,如MobileNet、ShuffleNet的分组卷积方式,通过分组的方式大幅度减少了计算量,同时在多个位置采用了分组卷积的特殊情况,Depthwise卷积,达到减少参数量的作用。前期测试了这2种基于ShuffleNet的改进方案,通过测试这两种方式效果良好。  #### 2.2 基于Transformer的Block构建 目前Transformer已经广泛应用于计算机视觉的各个领域。虽然Transformer模型通过self-attention机制缓解了cnn的缺点(例如感受野的局部性等),但其计算复杂度随着空间分辨率的增加呈二次增长,因此无法应用于大多数涉及高分辨率图像的图像恢复任务。CV领域中传统的self-attention机制(例如ViT, Swin-T),基于pixel级别计算pixel之间的attention矩阵。 为了解决高分辨率图像恢复中计算复杂度过高的问题,提出了基于channel维度的Restormer。通过这种方式有效减少了高分辨率图像任务中,计算复杂度过高的问题,同时更好利用了transformer的优势。经过测试,在block保持大致相同计算量的情况下,transformer的整体性能高于构造的ShuffleNet Block的性能。  后期仍有部分实验没跑完,通过阅读Megvii最新的论文《Simple Baselines for Image Restoration》,文中提出了目前许多SOTA方法使用了门控线性单元GLU,作者认为目前普遍使用的GELU激活函数可以看成是GLU的一个特殊情况,同时作者认为其点乘自带了非线性的成分,因此引入非线性激活函数也不是必须的,因此作者提出一个简单的SimpleGate去替代原有复杂的门控单元。后期也尝试在Transformer的forward里面引入SimpleGate,去替代Transformer block中前馈神经网络部分复杂的模型参数,去进一步减少参数,并获得更好的性能。 ### 3 基于Unet结构的多阶段特征融合 UNet最初用于图像分割领域,广泛应用于医疗影像处理的领域。UNet是一个典型的encoder-decoder网络,左侧经过下采样不断提取更加深层的特征;右侧通过上采样不断去解码。配合上中间的shortcut操作,得到最终相同尺寸的分割结果。 为了提升UNet的性能,我们希望在此基础上,添加辅助分支,达到更加优秀的网络性能。因此我们考虑三个方面,一个是在下采样阶段通过辅助分支提升网络性能。第二个是在上采样阶段,通过辅助分支更好的融合不同阶段的特征信息。第三个是从左侧到右侧的shortcut中,添加辅助组件,使得左侧的相对表层的信息能够和右侧经过更多层网络的信息进行更好的融合。 #### 3.1 下采样的信息融合 UNet的左侧下采样分支在进行的时候往往有多种下采样方式,例如通过池化层下采样,步长为2的卷积下采样,双线性插值的下采样,但是目前最常见的是采用PixelShuffle的方式进行下采样操作。在进行pixelshuffle操作之后,添加了一个1\*1的卷积降维,使得下采样之后的feature map实现尺寸减半,通道翻倍的效果。  考虑到单纯采用下UNet分支进行下采样操作, 在下采样的过程中,不容易保持图像的表层特征,为了使得能够更好融合左侧下采样支路的表层和深层特征,添加了基于双线性差值的辅助支路。本文将辅助支路和pixshuffle下采样的结果进行融合,然后再输入到下一层网络中。通过这两种不同下采样方式的融合,明显提升了最终模型的最终表现。 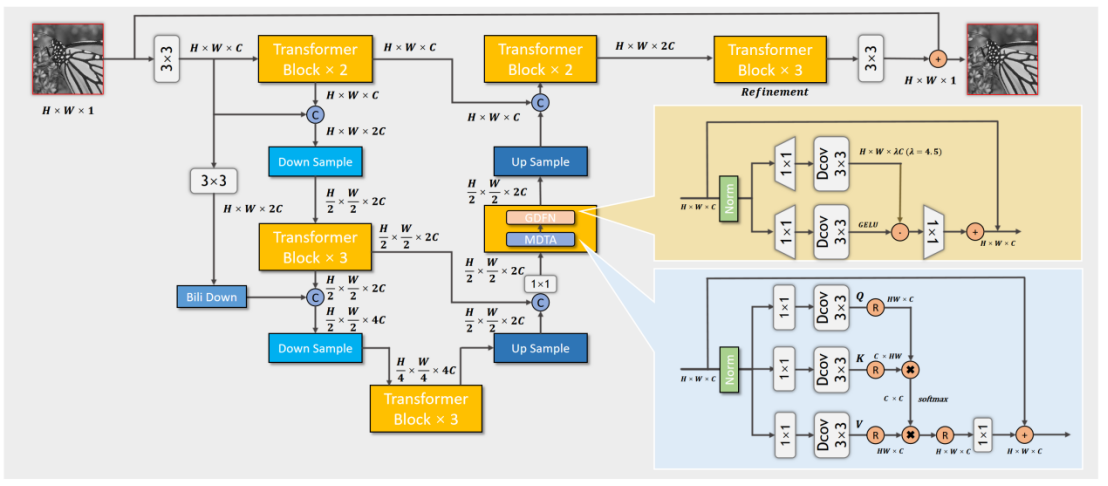 #### 3.2 多阶段输出信息融合 在网络的右侧上采样部分,之前仅依赖于最表层的block输出最终的信息,因此考虑将右侧三个不同尺寸的feature map进行融合,得到最终的输出结果。  该部分在融合的过程中采用了Attention机制,实现将三个不同尺寸的feature map通过双线性插值的采样方式,得到三个尺寸均为H×W×C的feature map。通过将三个feature map求和,利用平均池化层计算每个channel的注意力权重,然后采用三个卷积分别进行卷积操作,得到3个feature map的权重,计算softmax,最终将结果与原feature map点乘进行注意力加权求和。通过后期实验,通过将不同层级的feature map进行融合,最终结果也获得了一定的提升。 #### 3.3 上采样与下采样间的信息融合 这部分参考了Megvii的NBNet网络,该论文中提出了一个重要的SSA结构,通过将左侧经过更少层数网络的特征,通过投影的方式,映射到右侧经过多层网络的特征上面。该方式提出的思路十分新颖,同时作者通过在UNet网络上面,进行了SSA和普通Concat操作的交叉消融实验,可以看到起到明显的提升作用。  通过在中间shortcut支路上面添加SSA模块,实现对左侧下采样支路信息和右侧上采样支路信息进行融合,最终通过实验验证,也起到了良好的效果。 ### 4 实验与结果 实验结果受限于时间和算力因素,仅对部分内容进行了探索性实验,并没有进行完整的交叉验证,实验结果如下所示: #### 4.1 block之间的对比 该部分实验基于最初的UNet结构进行实验,仅改变了使用的block类型。通过调整block内部的参数量,使得模型参数都使其尽可能接近100k。 | Block类型 | Score | | :------------: | :------------: | | Shuffle v1 block | 8.7926(本地结果) | | Shuffle v2 block | 8.8114 | | Transformer block | 8.8884 | #### 4.2 多阶段融合对比 该部分实验基于transformer block构建的UNet网络,通过添加左侧辅助支路,右侧辅助之路和shortcut上添加了SSA模块达到更好的效果。 | 辅助融合支路添加情况 | Score | | :------------: | :------------: | | Transformer block | 8.8884 | | Transformer block + 注意力上采样 | 8.9129 | | Transformer block + 辅助下采样+注意力上采样 | 8.9768 | | Transformer block + 辅助下采样+注意力上采样+SSA | 8.9868 | #### 4.3 权重共享效果 该部分实验基于采用多阶段融合的UNet-Transformer网络,通过对于每个block组采用权重共享的方式,实现了效果的提升。最终以计算量能力有限的情况下,测试权重共享N=1,2,3三种情况,实验结果如下所示,目前N=3的情况下仍然观察到结果有所提升,并没有出现明显的收敛情况。 | 权重共享次数N | Score | | :------------: | :------------: | | 1 | 8.9868 | | 2 | 8.9949 | | 3 | 9.0009 | 经过最终的完善,最后模型总览图如下所示:  ### 5 总结 经过比赛结果验证,我们搭建的模型最终获得了第4名的成绩。虽然与前三名存在一定差距,但是也可以说明模型拥有较好的降噪性能。目前的实验仅针对于模型进行改进,对训练集和验证集合采用8:2的Hold-Out法进行划分,并没有对数据采取任何数据增强的操作。后期如果添加数据增强等策略,可能仍然会有一定的提升空间。 在模型Block构建上,通过CV领域这两年最新引入的Transformer,通过channel-attention计算将transformer使用在高分辨率的图像任务上面,并获得了较好的效果。在一定程度上也证明了,transformer不仅可以应用在大量数据大模型的场景下,在100k级别的小模型上面也可以起到良好的效果。 同时本文在UNet的基础上,提出了多阶段融合方式。通过添加更多辅助支路的方式,达到更好的性能。实验证明,在下采样阶段、上采样阶段和中间的shortcut阶段。通过添加辅助支路或者组件的方式,均可以使得模型达到更好的性能,与此同时也保证了模型大小始终控制在100k以下。 最后,为了提升模型性能,我们采用了权重共享的方式,进一步提升了模型性能。该方法虽然不引入额外的参数量,但是会明显增加模型预测的计算量,对所谓低功耗场景下的使用可能有相悖之处,因此该方式也仅适用于比赛提升成绩。 ### 参考文献 [1] L. Chen, X. Chu, X. Zhang, and J. Sun, "Simple Baselines for Image Restoration," p. 17. [2] A. Abdelhamed _et al._, "NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results," _ArXiv200504117 Cs Eess_, May 2020, Accessed: Apr. 15, 2022. [Online]. Available: http://arxiv.org/abs/2005.04117 [3] S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, "Restormer: Efficient Transformer for High-Resolution Image Restoration," _ArXiv211109881 Cs_, Mar. 2022, Accessed: Apr. 15, 2022. [Online]. Available: http://arxiv.org/abs/2111.09881 [4] C.-M. Fan, T.-J. Liu, and K.-H. Liu, "Selective Residual M-Net for Real Image Denoising," _ArXiv220301645 Cs Eess_, Mar. 2022, Accessed: Apr. 15, 2022. [Online]. Available: http://arxiv.org/abs/2203.01645 [5] Z. Wang, X. Cun, J. Bao, W. Zhou, J. Liu, and H. Li, "Uformer: A General U-Shaped Transformer for Image Restoration," _ArXiv210603106 Cs_, Nov. 2021, Accessed: Apr. 15, 2022. [Online]. Available: http://arxiv.org/abs/2106.03106 [6] S. Cheng, Y. Wang, H. Huang, D. Liu, H. Fan, and S. Liu, "NBNet: Noise Basis Learning for Image Denoising with Subspace Projection," in _2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)_, Nashville, TN, USA, Jun. 2021, pp. 4894–4904. doi: 10.1109/CVPR46437.2021.00486. [7] S. W. Zamir _et al._, "Multi-Stage Progressive Image Restoration," in _2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)_, Nashville, TN, USA, Jun. 2021, pp. 14816–14826. doi: 10.1109/CVPR46437.2021.01458. 最后编辑:2024年04月23日 ©著作权归作者所有 赞 0 分享

最新回复